When Apple deprecated OpenGL about 2 years ago we knew we had to find an alternative. I remember being upset, I just spent more than 3 years working on a new OpenGL render back-end for our creative coding engine. Yes, OpenGL is a ‘tad’ bloated, contains too many ‘deprecated’ extensions but is well known, relatively easy to use and (still) an industry standard. It ‘was’ also the only viable cross platform graphics API for a long time. The deprecation notice did not come as a surprise though, Apple has a tendency to break backwards compatibility in favor of new standards, often their own.
What frustrated me most was that there was no immediate alternative. Apple decided to not support Vulkan, only Metal. This infuriated me! It felt like a 'death sentence' from Apple to independent developers that work on cross platform (low-level graphics) solutions. Our clients use applications built with our engine on both macOS and Windows. We often deploy the final version on Linux for stability and maintenance reasons. Small teams (such as ours) don’t have the manpower to implement and support multiple low level graphics APIs for different operating systems. What was Apple thinking? Why only push your own standard? Why can’t Apple work together with the industry, are they not part of the Khronos group?
So next to not being able to use OpenGL on macOS and iOS there was no viable cross-platform alternative. The new generation graphics APIs (including DirectX12, Metal and Vulkan) are also notorious for being more difficult to implement, moving a lot of the logic previously managed by the driver to the developer. I understand the reasoning behind this decision and am willing to take the plunge, but not at the expense of implementing and maintaining 2 or 3 different low-level graphics APIs at the same time. Doing so would financially ruin my company and therefore wasn’t an option from the start. I know from first hand experience, working at a large AAA games company, how difficult this is.
Imagine my relief when Khronos announced the Vulkan Portability Initiative to encourage and enable layered implementations of Vulkan functionality including MoltenVK: a runtime for macOS and iOS that offers an (almost) complete subset of the Vulkan API implemented using Metal. A true hallelujah moment! I should be able to use the same code base to run high performance graphics applications on macOS, Windows and Linux. The world started to make sense again, not thanks to Apple, but Khronos.
Only question left to be answered: is MoltenVK any good? Yes, the demos will work, but what about applications developed with our engine? An engine that is not (primarily) made for games, but to visualize and solve ‘creative’ problems in the physical space. The only way to find out was to port it to Vulkan.
NAP applications do not dictate any sort of pipeline, including the graphics pipeline. Many games can be optimized because they render a single frame in a (very) specific way, for example: using x amount of frame buffers, in a certain order, with a known quantity of pipelines, shaders and buffers. I am aware this over-simplifies a typical render scenario for a game, but it helps illustrate my point. Because the game knows ‘how’ it is going to render ‘what’ you can be very explicit about your intentions up front. And Vulkan loves you being explicit about your intentions: perfect for a typical game-engine scenario, where there’s often only 1 window and a known quantity of shaders, frame-buffers, geometry and therefore pipelines.
Every NAP application, on the other hand, makes use of a completely different render pipeline. We don’t know in advance if and how many render targets (including windows) are spawned and how they are being rendered to. We don’t know which shader is going to render what type of geometry, and which attributes are updated at what point at runtime. That’s all up to the developer that writes the application. This freedom allows you to be ‘creative’, hence the phrase: ‘creative coding’ (which I hate, because it implies something else).
The end result is (often) a very straightforward, minimal pipeline, that draws exactly what you want and nothing more. This is ideal in situations where performance is crucial: NAP applications are (often) deployed on low spec devices with integrated graphics cards in industrial environments. Not on powerful gaming rigs with dedicated video cards and ‘infinite’ amounts of ram. Every compute-cycle and byte of memory counts.
The good: Vulkan allows you to be explicit. The bad: Vulkan wants you to be explicit up front. With OpenGL you can issue commands at any stage and have the driver figure it out, which is great but far from optimal in terms of performance. When using Vulkan those days are over. We had to completely rethink our graphics back-end to take full advantage of Vulkan without compromising the existing level of freedom we already provide in creating a custom render pipeline. On top of that: The render interface (used by clients) shouldn't change (unless necessary) and performance should be equally good, preferably better, than OpenGL.
Now, where to start?
It took us (a team of 3 relatively experienced ‘graphics’ programmers) approximately 7 months to port our entire render back-end from OpenGL to Vulkan. We didn’t work on the port full-time, often other work got in the way. I estimate that a single, well experienced graphics programmer, could complete this specific task in 3 months, working on it full-time.
Our goal was to reach feature parity asap, optimize where possible and make sure all NAP demos run equally well on Windows, Linux and macOS. If the Vulkan implementation was just as fast and stable as OpenGL, we would deprecate OpenGL in favor of Vulkan, completely removing OpenGL from our code base.
NAP uses SDL (simple direct media layer) to get cross-platform access to audio, keyboard, mouse, joystick, and graphics hardware. SDL already has built-in support for Vulkan, although information on how to set it up was (and remains) limited. I had to combine multiple sources of information to spawn a Vulkan compatible surface using SDL and a Vulkan instance. I decided to share my steps on Github. All things considered this was relatively straight-forward: Create a Vulkan window and Vulkan Instance using the required extensions and layers, select a GPU, create a surface to render to (based on window specifications) and make sure the GPU can present to it, create a swap chain and select a Queue. Your standard Vulkan initialization fare right? It just takes over 1000 lines of code.
At this point I realized how explicit Vulkan is. Nothing is left to chance and I absolutely love that after years of active OpenGL development. Finally a transparent way to inspect and select a GPU. No more implicit context creation. Proper support for sharing resources between multiple windows (without feeling disgusted), transparent handling of extensions and very good debug options (called layers, which you absolutely need if you’re serious about getting into Vulkan programming). The explicitness felt good.
We all know how the programmable pipeline works by now, otherwise you wouldn’t be reading this post, but that’s not enough. The moment you want to draw anything with Vulkan you are slapped in the face with synchronization primitives. And there are many, most notably primitives to synchronize GPU / CPU operations (fences) and primitives to synchronize operations on the GPU (Semaphores and Barriers).
I am not going to cover the ins and outs of Vulkan synchronization here. This post is about our porting experience, not the technical intricacies of the porting process itself. But if you’re interested in Vulkan Synchronization I highly recommend reading this article, it helped us a lot. Alternatively you can take a look at the NAP source code. Also: we’re not perfect, If you have any suggestions feel free to contribute!
Suffice to say that synchronization threw us (and I believe many with us) for a loop. What do I synchronize? Where? Using what? How does this example translate to our problem? Is the example correct? Especially that last question turned out to be relevant. Since Vulkan is relatively new and information is relatively sparse, you can’t be certain that what is shared is correct and when correct: the best solution for your problem.
One example we encountered early on had to do with the ‘Rendering and Presentation’ part of the Vulkan Tutorial. Initially ‘vkQueueWaitIdle’ is used, after that a semaphore is introduced to synchronize the operation on the GPU, based on a comment from a developer in the comment section. Later in the article a fence is introduced to ensure all commands associated with the previous frame are processed, but according to us in the wrong spot, causing the CPU to stall too early. It took us many hours, back and forth, to figure out the right approach, based on our specific needs, using various sources of information and the official Vulkan spec.
And that’s not an isolated case. We ran into similar issues trying to decide how to push changes to a shader (uniforms and samplers), how to properly allocate memory, when to use staging buffers and how many, how to destroy resources after hot loading content changes, how to organize our command buffers etc. The list goes on and on.
The main complaint coming from our developers was that existing information on Vulkan was either too low level (spec) or high level, with barely anything in between. Later I realized Vulkan is too hard to capture and generalize into solutions for common problems, due to the nature of the API. There are many ways to tackle a problem and the most optimal solution is most likely unique (at least to some extent) to your case, making it hard to generalize the ‘correct’ approach.
That Vulkan offers you this kind of control is great, it also means you could end up searching for the ‘right’ solution for some time, constantly questioning yourself, is this the right way? What are the implications of my decision? Luckily there are some options available to ease the development process.
This is hands down the best and most helpful feature to not only spot issues but also ease the Vulkan development process. We made extensive use of the ‘VK_LAYER_KHRONOS_validation’ layer, helping us to understand and resolve every reported warning and or error. Often our chosen direction turned out to be right, but the implementation not necessarily correct. The debug layers, almost always, pointed out the flaw in our thinking. An impressive and essential feature. Use them!
More than with OpenGL, having a good mental map of the GPU (physical device) and graphics pipeline, aided the implementation of certain features. For example: how to handle the double buffering of resources (such as dynamic meshes and textures), updating uniforms and samplers, when to delete resources etc.
Turns out: it’s not important to have a complete understanding of the ‘Vulkan API’. It’s better to map your decisions onto the hardware and apply those to the API. Because the driver does less, you do more, remember? This implies that you, at least partially, are the person writing the ‘driver’ (that’s how it feels). And drivers tell some piece of hardware, in this case the GPU, how to talk to the computer. It’s therefore important to have a good understanding of the physical layout of a GPU and how to address it. This, in turn, maps perfectly well to the Vulkan API and all the calls available to you. Once we reached this point of understanding, things such as synchronization (using barriers and semaphores) and memory management started to make more sense.
The following section contains high level information about the NAP Framework Vulkan implementation. It also explains which parts of Vulkan we misinterpreted when we started development and the design decisions we made.
Render commands are put in command buffers, these are processed by the GPU. Some commands contain data that is put into the command buffer as well. But most of the time, commands reference resources like textures, meshes and uniforms. You could say that this is similar to commands using data by value or by reference. When you submit a command buffer to the GPU, the GPU will start processing those commands. If you would wait for the command buffer to be finished, you would stall until the GPU is ready processing all of those commands. Instead, we submit our commands to the GPU and continue building a new command buffer for the next frame. So, the rendering of a frame on the CPU runs while the previous frame is rendered on the GPU. We need two command buffers: one that is being read by the GPU and one that is being written to by the CPU. This is double buffering, and we might also consider triple buffering. It just depends on how many frames you would like to have in flight at once. With triple buffering, the CPU won’t stall if the GPU is running an additional frame behind. The more buffers you have in flight, the higher the latency can be between a processed frame and the visual result on the screen, but there is less chance of the CPU being blocked by the GPU.
A frame processed on the GPU might reference a resource that is being processed by the CPU, running in parallel. A simple example is a texture on a mesh that you render in both frames. As long as the texture does not change, all is good. But what happens if we alter the texture while the GPU was processing a command buffer that refers to that texture?
Vulkan provides synchronization mechanisms to wait until the texture is not being used anymore on the GPU – the memory and execution barriers that we mentioned earlier. But in practice that would mean that we would need to wait for (a part of) the previous frame to finish before we can alter our resource. To make sure we can run frames fully in parallel, we decided to refer to a completely different texture with new contents in the new frame.
This applies to all mutable data. If you want to change a mesh or a texture, you need to provide a new mesh or texture with the new contents. But it doesn’t stop there. Uniforms are stored in Uniform Buffer Objects (UBOs) – another external resource. If you want to render your object at a new position, you need to provide a different UBO, set your matrix and refer to that UBO in your command buffer.
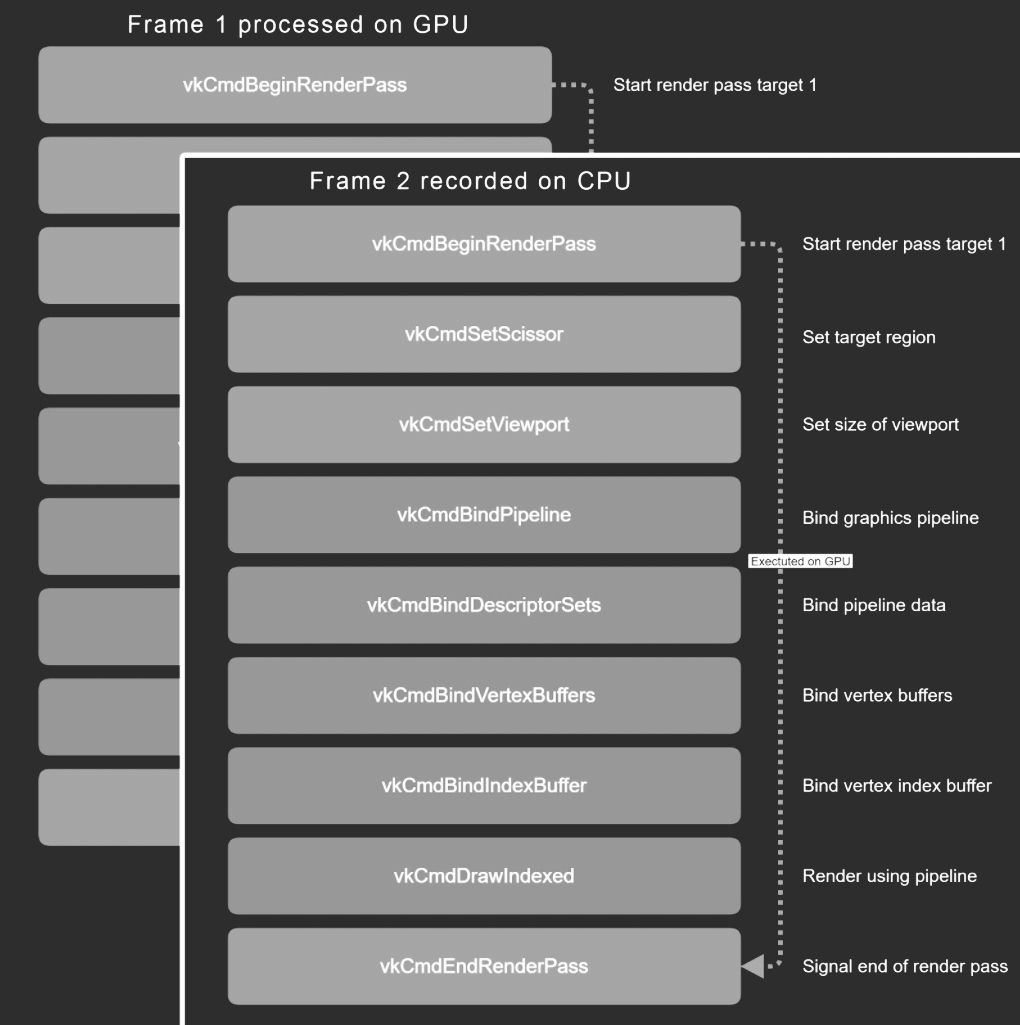
While you might think that this only applies to frames, it can also apply within frames. If you change the contents of a resource multiple times before submitting the command queue, all commands that refer to that resource will simply refer to the latest state. You are basically just overwriting the state of that resource for that frame. If you want to be able to use a resource multiple times within a frame with changing contents, you need to have multiple resources available as well, with unique contents. A good example is rendering an object on different positions within a frame: you would need multiple unique UBOs to accomplish this.
Note: Vulkan does provide ‘push constants’ for this particular case, where the matrices can be pushed onto the command buffer itself: a ‘by value’ operation. However, the amount of memory that is available for push constant is so small, that you can only reliably put two matrices in there. This does not solve the case for changing arbitrary uniform values within a frame, so we found this to be quite limiting and we therefore decided to solve this using UBOs instead.
In OpenGL, you never have to deal with any of these issues. If you update a texture, the driver will take care of managing those resources for you. In Vulkan, for each mutable resource you need to think about your multi-frame and inter-frame strategy. In NAP Framework, we introduced a concept of frames, and we use this concept to perform buffering of resources. We will show for each resource how this is performed.
Vulkan exposes quite a few concepts and at first, it’s hard to see what piece goes where because they don’t map to OpenGL as easily. Here are a couple of key objects and what they do:
When you get started with Vulkan, the data structures sometimes appear so rigid that it can be hard to understand how you should use Vulkan in scenarios where things are quite dynamic. An example is the Vulkan Pipeline object. A pipeline contains all of the GPU state like shaders, blend state, clip and view rect and it even refers to a Vulkan Render Pass. A Render Pass is bound to a render target. Because the pipeline’s clip and view rects have to be set and because you’d set them to the render target size by default, it appears as if the pipeline does not only tell you exactly how to render something, but also where you render it to. Creating pipelines is expensive, so you want to do this in advance as much as possible. But you don’t know in advance where you’d like to render something to. This can be very dynamic. Do you need to create pipelines for each render target you could possibly render to? Is that even feasible? And what if you want to change a blend property? It appears as if Vulkan wants to pin down as much state as possible, which may be confusing and hard to fit into your engine. But, things are not quite as they appear, or at least appeared to us.
Initially, we got the impression that a Vulkan Pipeline dictates the how, where and even what you are going to render. But that isn’t the case, it only describes the how, and only partially. Let’s look at a couple of things:
A render pass describes where you render to, how a render target is cleared, and some synchronization properties. A Vulkan Pipeline does refer to a Render Pass, but it only needs to be compatible with a render pass. You can still use the same pipeline to render to multiple different render targets using multiple render targets, as long as the render targets are compatible.
The pipeline still refers to clip and view rect, and they have to be set. By default you’d set these to the render target’s size. So there still appears to be a tight link to render targets. However, the clip and view rect can be changed to be set dynamically as part of the command buffer. We can set the clip and view rect globally and only override it where we need to. This is exactly what we need.
The only relationship between a mesh and a pipeline is the draw mode: POINTS, LINES, TRIANGLES, and so on. This property is not a strong coupling between mesh and pipeline. The only thing that we need to make sure of, is that when we render a mesh using a pipeline, that the mesh is actually compatible with the shader in the pipeline. We verify this when creating a RenderableMesh, quite similar to how we did this in OpenGL.
Uniforms and samplers are all set through Descriptor Sets. For each draw call, a Descriptor Set needs to be bound. So, what textures are being used and what uniform values are used is all determined dynamically.
If we simplify the Vulkan calls for a typical frame, in this case rendering 2 objects each to a different window, the call stack looks like this:
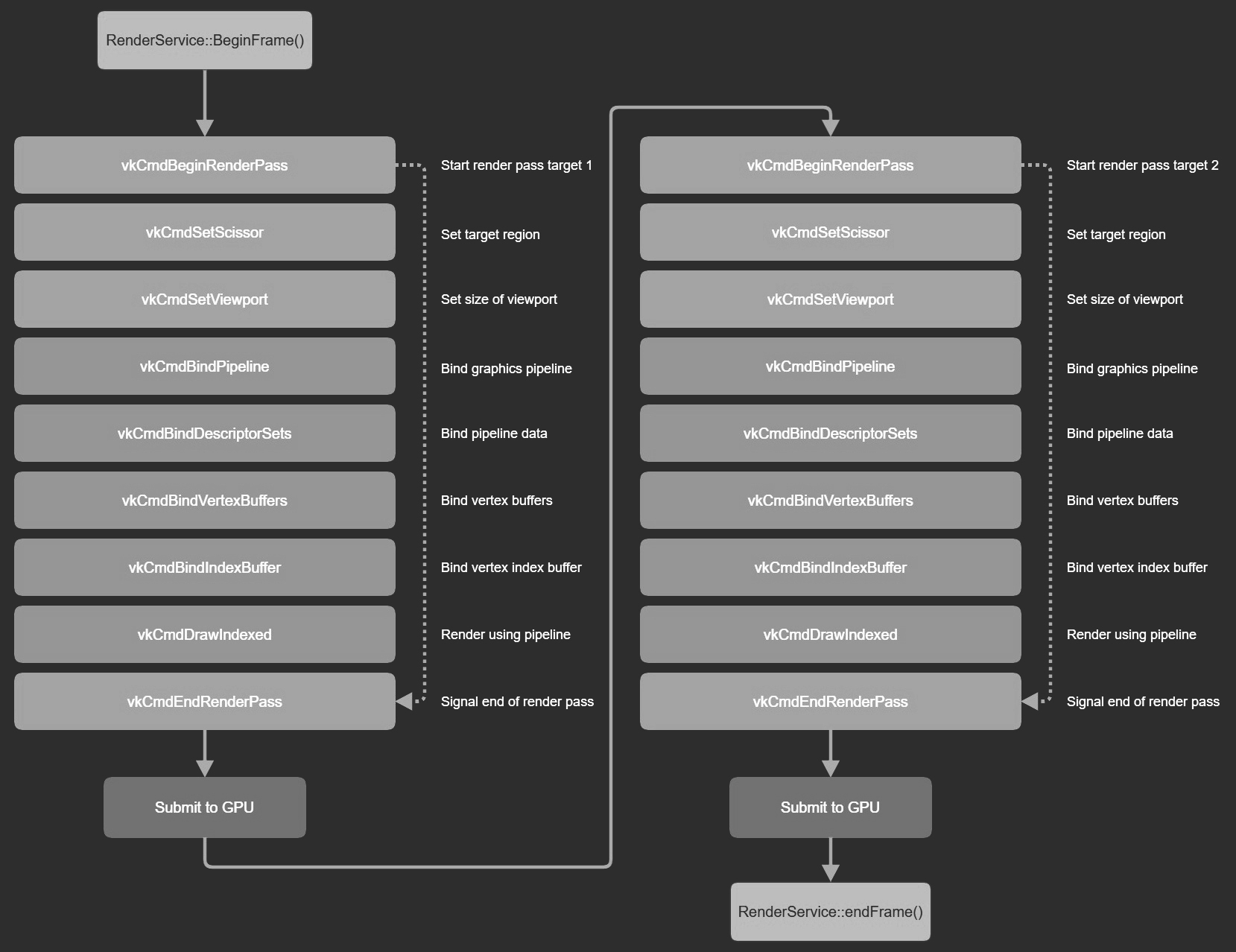
From this loop, you can probably spot opportunities for optimization. If a pipeline is shared for multiple objects, you only need to set it once. We could also record the command buffer, each associated with a different window, on a different thread. However: the potential gain in performance currently doesn't justify the added level of complexity to add synchronization. Especially for your typical NAP application, it would just clobber the render interface. More advanced users can however write custom NAP render components to minimize pipeline swithches. In OpenGL, drivers tend to perform a lot of work to cache render state and to minimize state changes. Once everything is in place using the Vulkan pipeline object, this process becomes a lot easier.
Now that we understand the role of the Vulkan Pipeline better, we also better understand how we should treat it. it’s good to think about how many pipelines you expect to have in your engine or application. Again, our initial thought was that we'd have many because we overestimated the responsibility of the pipeline object, but once we understood the pipeline better, we realized there aren’t that many pipeline objects at all. It is currently parameterized by the following properties in NAP Framework:
How many combinations of these properties do you expect to have in your application? We expect them to be fairly limited. We also heard about a AAA game that only has about a hundred pipeline objects that they create in advance.
Creating a pipeline is expensive. Vulkan recommends to create as many of them in advance. So our initial thought was to move the pipeline creation to initialization. We struggled with this approach and moved from design to design a couple of times. For instance, in the NAP Framework Material design, there are multiple places where one of the aforementioned properties can change: in the Material or MaterialInstance. We had to implement a serious amount of callbacks and other logic to be able to create new pipelines on the fly when properties changed. It felt like we were fighting with Vulkan more than we’d like.
Once we realized how few pipelines were actually required and how much freedom it would give if we allocated pipelines lazily, we started building a pipeline cache. For each object that you draw, you simply acquire a compatible pipeline from the RenderService:
The pipeline cache will only contain a limited amount of objects and a lot of objects share the same pipeline, so the warmup of the cache won’t be as much of a problem. If it does happen to be a problem, it’s good to look at ways to ‘hint’ or ‘warmup’ the cache in advance for certain objects.
A DescriptorSet binds runtime data to a shader. This sounds pretty trivial but it turned out to be one of the most complex areas of our Vulkan integration. When you draw an object, you call vkCmdBindDescriptorSets to bind textures and uniform values for that draw call. Uniform values are passed to the shader in memory blocks called Uniform Buffer Objects (UBOs). As described earlier, the command buffer will then contain a reference to the UBO via the DescriptorSet.
These UBOs contain every type of uniform data, including model / view & projection matrices. Our basic assumption was that we’d like to keep the OpenGL freedom of being able to set uniforms before each draw call, even if there are multiple draws per frame. The reasoning behind this was that NAP is very versatile in its drawing. We may want to draw a single object multiple times, but we may also want to draw it multiple times to multiple windows. And we would like to keep the flexibility to change uniform parameters on the fly within those draw calls.
That means we need to deal with changing state within a single frame. Normally you would like to create DescriptorSets in advance, and buffer them for each frame that you have in flight. But this becomes problematic because we cannot predict anymore how many of these DescriptorSets (and UBOs) we want to have in advance.
A secondary complication is that we can’t make any assumption on how previous frames left the state of a Descriptor Set or UBO. In other words: ‘dirty’ mechanisms and other ways to avoid updating a UBO become harder. We’ll see the effects of this in a moment and how we can potentially fix that later.
Instead of having a double buffered DescriptorSet in MaterialInstance, we decided to create a DescriptorSetCache and acquire a DescriptorSet on each draw, similar to how we acquire a pipeline object for each draw. The cache internally maintains a free-list of DescriptorSets. When an object is not in the free-list, we allocate a new one. When we advance in frames, any used DescriptorSets are pushed back onto the free-list. An upside to this approach is that this works regardless of the amount of frames you have in flight: a frame just pulls items off the freelist, regardless of the frame it was previously used in. As mentioned, we cannot make any assumption anymore about the state of the DescriptorSet and its content, because the content could have been updated in any of the draw calls of the previous frames. This means we push all the content when a descriptor set is requested. However, the amount of work we do to update the DescriptorSet is very minimal.
A DescriptorSet binds a certain amount of samplers and textures, and those samplers and textures need to have the same shader bindings. So a single DescriptorSet is created for a specific shader and cannot be reused for another shader. Well, in theory they could be shared if the shader’s interfaces match each other exactly, but in any other case, this is not possible.
Vulkan has support for allocating DescriptorSets from a pool, but the allocation mechanism is rather strange and it has the effect that a pool can only reliably hold a fixed number of DescriptorSets of the same type. We’ve modeled our DescriptorSetCache around these pools. A single DescriptorSetCache manages a growing number of pools of a fixed size, all bound to the same type of descriptor. This means that we first need to acquire a DescriptorSetCache from a global group of DescriptorSetCaches, given a certain shader layout. In practice you will have as many DescriptorSetCaches as you will have shaders. But other than that, the caches are shared across material instances.
To summarize how DescriptorSets are acquired:
MaterialInstance.We would like to be able to perform some form of dirty checking, to avoid updating any data when it is needed. The only way we see that this could be possible is by maintaining a content hash that describes the content of what textures were bound and what uniform data is bound. That hash could then be stored for each item in the DescriptorSetCache as well, and it could be passed as an argument to the acquire method. The cache would then prefer to return an item from the free-list with the same hash. If such an item is returned, no updating would be required.
Textures can be used in a variety of ways:
In OpenGL, all of this is rather easy. However, in Vulkan, we have to deal with all of the synchronization that is involved. And we want to make sure that we’re not allocating too many buffers for cases where it is not needed. For instance, static textures do not need any form of double buffering at all. Important to note is that contrary to uniform values, we decided not to support changing textures within a frame. There are two reasons for that:
We use a staging buffer to upload the content of a texture from the CPU to GPU. We perform this copy by putting a copy command on the command buffer through vkCmdCopyBufferToImage. The number of required staging buffers varies per type:
Textures can only be updated outside of a RenderPass. We added dedicated logic to the RenderService to upload textures at the beginning of each frame, before a RenderPass is activated. The Texture requests an update when the content of a staging buffer changes. If the amount of staging buffers would be equal to the amount of frames in flight, we would not be able to update the staging buffer outside of a frame. There is a very simple fix for this: if we allocate one additional staging buffer, there will always be one staging buffer available outside of the render frame.
How does the material know what texture to use? This is best explained by looking at the flow of commands: Texture2D::update is called somewhere in the application with new texture contents. We write the content to a staging buffer that is guaranteed to be free. We signal RenderService that at the beginning of the next frame, it needs to start a transfer.
RenderService::beginFrame calls Texture2D::upload, which puts a transfer command on the command buffer. The current image index points to the new texture and the notifyChanged signal is called. The Material responds to the signal and updates the internal DescriptorImageInfo to point to the new texture. The nice thing about this approach is that there is a single code path for static and dynamic textures.
Meshes in NAP are either static or dynamic and contain at least 1, but often more, attributes. The number of attributes and their intended use is competely open and customizable. Every attribute is a vertex buffer that has a CPU and GPU representation.
Static meshes use a Vulkan staging buffer to copy the vertex buffers from the CPU to the GPU. As with static textures, the content of the staging buffer is copied to the GPU buffer at the beginning of a new frame. Because the staging buffer is no longer needed (the mesh won't be updated) it is scheduled for destruction.
Dynamic meshes (contrary to Textures) are not copied to dedicated GPU buffers but, depending on the hardware, a slower set of shared CPU / GPU buffers. This is because dynamic meshes are updated every frame, contrary to a texture, which is updated less frequently. The therefore required number of CPU / GPU copies would have a negative effect on performance, removing the benefit of being able to read from a dedicated GPU buffer when rendering. For this reason the NAP default is 'static'. As with textures, the number of staging buffers equals the number of frames in flight + 1, for the same reason textures do. We might add another mode for meshes that are updated (after the initial upload) but less frequent.
We have chosen a specific way to organize our command buffers for NAP Framework. This goes quite deep into Vulkan and is related to how Vulkan handles command buffers and synchronization. We will highlight the most important aspects and explain the choices we made.
An important part about command buffers is understanding how ordering works in Vulkan. I find it easiest to think about command buffers as one giant stream of commands, spread across multiple command buffers that are submitted over time. If you let go of the ‘frame’ idea for a second then the idea of a large stream of commands becomes easier. When you think about ordering commands in this giant stream, there is a natural hierarchy. First, commands within a command buffer have a specific order. Then, between command buffers, the ordering depends on the submission time of the command buffer as a whole. The hierarchy goes even further in Vulkan, but this is where it ends for our purposes.
All of this ordering is about ‘submission time’ ordering: it tells you when commands were submitted to the GPU, but not at all when they are finished. Synchronization through memory and execution barriers work entirely on this submission order. You can create barriers for ‘everything that happened before me’ or ‘everything that happens after me’. An example of this is our texture usage. We put a command on the command buffer to transfer a staging buffer to a target texture. A later command then uses that texture. But there is no guarantee that the transfer has finished before we want to use it. All of the dependencies between commands in the command buffer need to be explicitly synchronized using the Vulkan synchronization mechanics. So we insert a barrier that tells the GPU: when a subsequent command in the command stream wants to read from this resource, wait until transfer is completed.
In all of this it is important to realize that there is no implicit synchronization between command buffers. If you perform a submit of a command buffer, and then another command buffer, there’s zero guarantee that commands in the first command buffer will be finished before commands in the second command buffer. It’s still one giant stream without guarantees when commands are finished. For example, we could submit our texture transfers in a single command buffer and then use the texture in a later command buffer. We still need to put explicit synchronization commands in one of the command buffers for this to be safe.
We decided that each render window manages its own double buffered command buffer. When beginRecording() is called, the current command buffer for that target is set and all commands will be recorded in that command buffer until endRecording() is called. On completion the command buffer is immediately submitted to the GPU, ready to be processed. But we still need to do two things, we want to:
Because of the Vulkan requirement to transfer data outside of RenderPasses, we maintain a separate command buffer just for data transfer. As explained, we need to take care to put barriers in place in this command buffer to make sure that a subsequent read from the texture will be blocked until the transfer is ready.
To support headless rendering, we use another command buffer. This command buffer is used during the RenderService::beginHeadlessRecording and RenderService::endHeadlessRendering calls.
We perform a little trick to synchronize all these separate command buffers into ‘frames’. On RenderService::endFrame(), we submit an empty command buffer together with a fence. When we wait for that fence to be signalled we know all commands, up to that point in the frame, have been processed on the GPU
It was a wish for us to maintain the OpenGL coordinate space in Vulkan. OpenGL consistently uses the bottom-left corner as its origin (0,0), Vulkan consistently uses the top-left corner as its origin. If we want to keep using the OpenGL coordinate space, it appears as if a simple y flip in the projection matrix would suffice. That goes a long way until you start to use texture render targets. We dug into this issue and found a wealth of misinformation on the internet, so here’s an explanation on what happens.
When you think about sampling textures, the notion of a bottom-left or top-left corner is vague. What does it mean exactly? It becomes easier when you let go of that idea and start thinking about data in its raw form. Any API (OpenGL, Vulkan, DirectX) all have their origin set to the first byte in memory of a texture. So, if you upload the texture the same way in all APIs and sample (0,0) in any API, you will get the same value back. If your paint program stored the top-left corner as its first byte on disk, and you load this into OpenGL using glTexImage2D, contrary to what you perhaps would think, the top-left corner is returned. The reason it works this way is because glTexImage2D expects the first byte to be the lower-left corner of the texture:
The first element corresponds to the lower left corner of the texture image. Subsequent elements progress left-to-right through the remaining texels in the lowest row of the texture image, and then in successively higher rows of the texture image. The final element corresponds to the upper right corner of the texture image.
But we didn’t upload it this way. We uploaded the logical top-left corner of the image as the bottom-left. And when we sample at (0,0), it will sample what OpenGL considers to be the bottom-left corner. The ‘correct’ way to do this in OpenGL is to actually flip the contents of the image before uploading, and inverse the vertical texture space compared to other APIs. But that is all rather senseless because the result is the same.
If you start thinking less about top-left and bottom-left and start thinking more about the raw data, it becomes a lot easier to reason about. However, the part where top-left and bottom-left become relevant is when you start using render targets. When you render to a texture using a render target, there is an absolute top-left defined in image space. In other words: the render target will store its first byte differently in OpenGL than in Vulkan. As long as those spaces are consistent, everything will be fine. But if you mix them, things are not, which is what we have here: we have an OpenGL texture space, but a Vulkan way of writing to a render target. After you render to a texture using a render target, and subsequently use that texture, the texture will be vertically flipped.
What you could do is invert the entire scene vertically, when rendering to a render target. This could be done using the projection matrix, but Vulkan has a special little hack for this, and that is to invert the viewport. On beginRendering() we actually use a viewport with a negative height to accomplish this, just for render targets. But we’re not done. The inversion causes the winding order of our triangles to be reversed. So, when rendering to a render target, we also flip the winding order in our pipeline.
At the time of porting, MoltenVK only supported Vulkan version 1.0. This meant we were bound to version 1.0 for our engine. However, because we invert the viewport (to minimize content changes) the VK_KHR_maintenance1 is required. This extension was at the time already supported on all platforms.
After having ported the render-backend (together with all demos and additional content) on Windows, we moved to Linux and macOS.
We only support the latest LTS version of Ubuntu, in this case 20.04. Compiling (GCC) and getting it to run turned out to be a walk in the park. Everything was up and running within a day, we only had to resolve some minor swap chain issues when resizing a window and add Vulkan to our build system. Other than that most things worked as expected. Both integrated and dedicated GPUs worked. Next!
Getting the port to run on macOS (Catalina) took approximately a week and wasn’t as smooth of a process as with Linux, but then again, I did not expect it to be, considering we’re dealing with Apple and MoltenVK. The main issue we faced, after deciding to use the Vulkan Loader (instead of linking directly to MoltenVK), was that everything rendered fine on integrated cards but failed to render on dedicated cards, except for the GUI. It was immediately clear this had to do with memory allocation, because NAP uses the vma_allocator, where imGUI uses default vulkan allocation objects. But why were we not seeing the same issue on Windows and Linux? Isn’t the entire point: One API to rule them all?
Turns out we forgot to set the VK_MEMORY_PROPERTY_HOST_COHERENT_BIT when creating a staging buffer. After that everything worked as expected. An impressive feat considering macOS doesn’t have native Vulkan support. Chapeau to the people at MoltenVK!
I will dedicate a different article to the performance gains, including benchmarks. But overall most demos and applications run approximately 5-25% faster on Windows and Linux, depending on the complexity of the scene and final optimization of the render pipeline. As always: this is just the beginning, there’s room for improvement. But the initial results are very promising.
On macOS the gains are more substantial. Because Apple deprecated OpenGL and stopped supporting it a long time ago, performance has been particularly bad. Often the same NAP application would run at ~half the speed (on similar hardware) on macOS in comparison to windows. That’s no longer the case.
I was initially skeptical about the use of MoltenVK, being a translation layer to Metal, but as it turns out, all apps run just as well on macOS as they do on Linux / Windows, with the use of MoltenVK. This is something I'd like to highlight more, and stress the importance of. Without Vulkan we would have to implement a special Metal render back-end just for macOS users, something not doable for a relatively small company such as ours. Having switched to Vulkan dramatically improved render-times for our mac users.
I can’t say this was easy (far from it) but in retrospect absolutely worth it. Vulkan does feel like the future of graphics. The growing level of complexity developers are confronted with on a daily basis justifies (in my opinion) the existence of low-level specialized APIs such as Vulkan, there’s no way around it. I am looking forward to learning more and improving our engine, even if that means smashing my head against the wall from time to time.
NAP Framework is open source software. Suggestions and contributions are welcome.
NAP 0.4 is now available for download and ships with Vulkan instead of OpenGL
Coen Klosters
Lead Developer NAP Framework
Technical Director Naivi
Special Thanks: Jelle van der Beek & Ritesh Oedayrajsingh Varma
